Nettverksorganisering i webmediet – En gjennomgang av tre sentrale fenomener på World Wide Web
Av Vegard A. Johansen
Speciale i Film- og medievitenskap
Det Humanistiske Fakultet,
Københavns Universitet. Juli 2004
Veileder: Mikkel Weider
Oppsummering
Oppgaven er mitt speciale / min hovedfagsoppgave i film- og medievitenskap ved Københavns Universitet, sommeren 2004.
Oppgaven tar for seg forskjellige modeller for informasjonsorganisering og -presentasjon, og viser noen fordeler og bakdeler med de forskjellige. Et utgangspunkt er at en nettverksmodell for organisering og presentasjon ikke har vært så sentralt på web, til tross for at det er en nettverksmodell som ligger til grunn for organiseringen av Internett som helhet.
På denne måten har oppgaven et overordnet teoretisk utgangspunkt, men er gjort så praktisk som mulig ved å ta utgangspunkt i tre sentrale fenomener og suksesshistorier på web i dag, og viser hvordan disse fenomener nytter nye modeller for organisering og presentasjon til sin fordel.
De tre fenomener som er valgt er: søkemaskiners viktighet i 2004, med spesiell fokus på hvordan Google nytter nye modeller for å presentere og behandle sine data. Personalisering på web, med utgangspunkt i hvordan Amazon personaliserer sitt websted, og bruker nye modeller for å samle inn data, og legger opp til en annen navigasjonsmodell enn det som har vært mest normalt. Til slutt weblogs, og hvordan disse er holdt sammen, med spesiell fokus på hvordan teknologier knyttet til det semantiske web brukes i større grad enn man har sett før.
Det var et mål å skrive en dagsaktuell oppgave, og gi et bilde av noen sentrale fenomener man ser på web i 2004. Kommentarer, ris, ros og denslags må gjerne legges inn her.
Innholdsfortegnelse
(Oppgaven var på 82 sider i innlevert versjon)
- 0.0: Prolog
- 0.1: Innledning og problemformulering
- 0.2: Fremgangsmåte
- 0.3: Metodiske overveielser
Del 1
- 1.1: Nettverksorganisering og sentralstyrt organisering
- 1.2: Internetts histore, og webmediets konseptuelle bakgrunn
- 1.3: Evolusjonen av websteder
Del 2
- 2.1: Vår tilgang til medier, tidlige organiseringmodeller og tidlige søkemaskiner
- 2.2: Google Incorporated oppstår
- 2.3: Pagerank
- 2.4: Annonser på web – AdWords og AdSense
- 2.5: Oppsummering
Del 3
- 3.1: Personalisering i webmediet
- 3.2: Amazons historie
- 3.3: Personalisering hos Amazon.com
- 3.4: Amazon som nettfellesskap og overbevisende teknologi
- 3.5: Oppsummering
Del 4
- 4.1: Bloggens historiske bakgrunn og utbredelse
- 4.2: Bloggens kjennetegn
- 4.3: Typologisering av nettfellesskaper
- 4.4: Weblogs og det semantiske web
- 4.5: Oppsummering
Del 5
- 5.1: Oppsummering
- 5.2: Perspektivering
Del 6
Prolog.
I mine studier har jeg hele tiden vært opptatt av formidling i digitale medier, først med henblikk på computermediert kommunikasjon innenfor forskjellige nettfellesskaper, men i de siste år mer fokusert på webmediet alene.
Høsten 2003 hadde jeg praksisplass som brukervennlighetskonsulent i firmaet Grey Digital, og arbeidet tett med flere prosjekter hvor vi evaluerte websteder i forskjellige faser i utviklingsprosessen, samt bisto i den overordnede konseptuelle utviklingsfasen. Våren 2004 fortsatte jeg i firmaet, denne gang som hospiterende specialeskriver.
Gjennom mange år har jeg drevet som webutvikler både som hobby og på profesjonell basis, og har etterhvert erhvervet meg en del kunnskap både om praktisk og konseptuell webutvikling. Det er disse erfaringene og denne kunnskapen jeg ønsker å sette inn i en ramme i dette specialet.
Det har vært et mål å skrive et aktuelt speciale, og komme frem til noe kunnskap som kan brukes i praktisk og konseptuelt utviklingsarbeid.
0.1
Innledning og problemformulering.
“Networks are very old forms of human practice, but they have taken on a new life in our time by becoming information networks, powered by the Internet”
– Manuel Castells
En stor tendens vi har sett de siste tiårene er en vekst av nettverksorganisering som den foretrukne modell for organisering virksomheter, samfunn og økonomi. En utvikling som henger sammen med andre store utviklingstrekk vårt samfunn har gått gjennom – som globalisering, internasjonalisering, sekularisering o.a. En rekke utviklingstrekk med det til felles at de har gjort vårt samfunn større, mer komplekst og mer fragmentert.
Et fragmentert samfunn har behov for organiseringsformer som tar hensyn til dette, noe som har ført til at fremstående teoretikere som Manuel Castells har befattet seg med Internett og nettverksorganisering som det 21. århundrets foretrukne organiseringsmodell, metafor og styringsprinsipp for samfunn, økonomi og kommunikasjon – en fleksibel og tilpasningsdyktig modell, egnet til de utfordringer et fragmentert samfunn gir. Internett er kanskje den mest eksplisitte nettverksorganisering vi har sett, et godt eksempel på nettverkmodellens styrker, og det Castells ser på som motor bak denne utviklingen.
Men tross sine mange styrker, har nettverksmodellen også klare svakheter. Når det kommer til å koordinere oppgaver og fokusere ressurser mot et gitt mål har andre, mer sentralstyrte, organiseringsmodeller tradisjonelt vist seg å være mer effektive.
Fokus i denne oppgaven er webmediet, og hvordan man har tenkt informasjonsformidling og informasjonsorganisering her. Gjennom webhistorien har man tradisjonelt støttet seg til en mer sentralstyrt modell for formidling av innhold og for å styre lesning, men noen sentrale fenomener vi ser på web i dag peker på at dette er i ferd med å endre seg. Det er ved hjelp av disse fenomener, og med utgangspunkt i de forskjellige organiseringsmodellers styrker og svakheter jeg ønsker å se på hvordan man kan nytte en nettverksmodell for informasjonsorganisering og informasjonsformidling. Jeg vil se på de fordeler dette har, de problemer det byr på, og hvordan tre sentrale fenomener på web har klart å utnytte noen av nettverksmodellens prinsipper til sin fordel.
0.2
Fremgangsmåte.
Jeg vil bruke første del av oppgaven på å etablerer mitt domene bedre ved å identifisere de forskjellige organiseringsmodeller som finnes, samt deres styrker og svakheter.
World Wide Web er fokus her, et medie som har gått gjennom store forandringer siden dets gjennombrudd for rundt ti år siden. For å kunne identifisere disse forandringer er det sentralt å kjenne til historien, og det konseptuelle tankegods bak, mediet.
Et sentralt poeng er at hvor Internett som helhet er basert på, og fungerer på grunn av, en nettverksmodell, har dette ikke i like stor grad vært tilfelle for hvordan man har tenkt informasjonsorganisering i webmediet. Jeg mener dette er i ferd med å endre seg, og for å belyse dette vil jeg utover oppgaven ta for meg noen sentrale fenomener og suksesshistorier som har oppstått på web de senere år. Fenomener som ved første øyekast kan virke urelaterte, men som har det til felles at de nettopp nytter en nettverkstankegang som prinsipp for informasjonsorganisering og -formidling på nye måter.
Jeg vil bruke tre sentrale cases som belyser dette fra forskjellige sider. Det første jeg vil se på er hvordan vår tilgang til informasjon har forandret seg, med utgangspunkt i søkemaskiner og hvordan Google bruker nye prinsipper for å samle og presentere informasjon.
Videre vil jeg se på noen formidlingsprinsipper og -konvensjoner som har forandret seg, og hvordan spesielt Amazon de siste år har gått nye veier i å formidle sitt innhold, en formidling gjort mulig av kreativ utnyttelse av kundenettverk og registrering av adferd.
Det siste fenomen jeg vil ta for meg er weblogs, og hvordan disse fungerer som et nettfelleskap, og fundamentalt skiller seg fra tidligere kjente nettfellesskaper. Sentralt her er hvordan nettverksmodellen har ført til eksperimentering med nye teknologier for spredning og lesning av fellesskapet – teknologier som hører under det vi kjenner som det semantiske web.
Et sentralt poeng med å ta for meg noen av de mest åpenbare suksesshistorier i webmediet er at man på denne måten kan få et oppdatert bilde av hva som skjer i webmediet i dag, at man muligens kan lære noe av dem, og at man ved å analysere disse kan få noen tanker og perspektiver på hvordan webmediet kan utvikle seg fremover.
Før jeg kommer så langt vil det imidlertid være nyttig å etablere mitt domene bedre. Jeg vil først etablere hva vi mener med nettverksorganisering, hvilke andre former for organisering vi har, og hvilke styrker og svakheter de forskjellige har. Videre kommer en historisk gjennomgang av Internett og webmediet for bedre å kunne identifisere de forandringer som har skjedd.
0.3
Metodiske overveielser.
Ønsker man å skrive et dagsaktuelt og praktisk rettet speciale har dette implikasjoner for det metodiske. Flere av de fenomener jeg tar for meg, både for å belyse historien, og som utgangspunkt for videre anlyse er dårlig beskrevet i den akademiske litteraturen. Og videre vanskeliggjør Internetts skiftende natur tilgangen til konkrete historiske data.
En konsekvens av dette er at jeg har vært nødt til å finne mange av mine kilder på nettet selv. Dette fører til en eklektisk kildebruk, som også avspeiler seg i oppgaven. Det fører også at få kilder har blitt brukt som primærlitteratur, og at tolkningen og bruken av kilder i et større perspektiv ofte har vært mer sentral.
Man kunne angrepet de forskjellige tema og fenomener jeg tar for meg på andre måter, også mer forankret i den klassiske litteraturen, men en fare med dette er at specialet kan bli skrevet på et metanivå, og at man mister noe av det dagsaktuelle og praktiske i prosessen. Jeg føler min tilgang er riktigere med tanke på mitt tema og min målsetning.
Del 1
1.1
Nettverksorganisering og sentralstyrt organisering.
“Networks have extraordinary advantages as organizing tools because of their inherent flexibility and adaptability, critical features in order to survive and prosper in a fast-changing environment.”
– Manuel Castells (2001: 1)
Sitatet over beskriver Castells fokus og utgangspunkt for analyse, så vel som å si noe om nettverkmodellens fordeler i forhold til andre modeller for organisering – hos Castells vertikal organisering og hierarkisk organisering. Denne oppgaven har samme overordnede fokus, men fra et annet perspektiv. Jeg vil fokusere på nettverksorganisering, nettverkstankegang og informasjonsformidling innenfor ett domene, nemlig World Wide Web.
For å etablere dette domenet vil jeg først se på hvordan man kan organisere informasjon gjennom hypertekst, og også her ser vi en tredeling mellom nettverksmodellen, den vertikale organisering og hierarkisk organisering.
Michael Barner-Rasmussen opererer i sin artikkel “En model for analyse og produksjon af hypertekst” med tre fundamentale topografier for hypertekst, og definerer topografi som “hypertekstens makrostruktur, dvs. det mønster eller landskab, som hypertekstens tekstdele og deres linking tegner.” (Barner-Rasmussen i Jensen 1998: 160, min kursivering). Jeg vil ikke gå så mye inn på Barner-Rasmussens teorier, men de tre topografier illusterer de forskjellige organisasjonsformer på en god måte, som ses i figuren under.
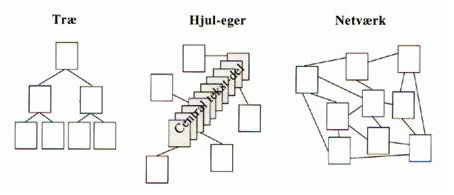
Tre-topologien, eller den hierariske organisering er kanskje den eldste organiseringsformen som finnes, og vanskelig å komme utenom både med tanke på organisering av informasjon og annet, både på web og innenfor andre domener. Innenfor samfunnslivet kjenner vi den som byråkratiet, og på websteder kjenner vi det som den fundamentale inndelingen i hovedområder og underområder. Innenfor byråkratiet fungerer det slik at noen har det overordnede ansvar, og oppgaver og ansvar blir delegert nedover i systemet. På web baserer det seg på et prinsipp hvor brukeren på diverse tidspunkt må ta noen fundamentale valg med tanke på hvilken retning lesningen skal fortsette i.
Hjulager-topografien, eller den vertikale organisering, har flere likhetstrekk med den hierarkiske organisering, men er ikke så strengt inndelt i flere lag for beslutningstakning. Innenfor samfunnsliv og bedrifter kjenner vi dette som utdelegering av oppgaver til flere mer eller mindre selvstyrte enheter, men som alle bidrar til et sentralt mål. Innenfor web og informasjonsformidling er det en modell som baserer seg på at lesning skal gå fra start til slutt, men hvor man kan ta avstikkere underveis, og kan sammenlignes med en bok hvor fotnoter og referanser fungere som lenker – referanser som har det mål å støtte teksten.
Som organisasjonsprinsipp har disse to modellene tradisjonelt vært foretrukket grunnet modellenes evne til å koordinere funksjoner, fokusere ressurser mot et satt mål og løse spesifikke oppgaver (Castells 2001: 2).
I denne oppgaven vil jeg slå disse to modellene sammen, og vil fra nå av omtale dem som sentralstyrte modeller, da det er sentralstyringen som skiller dem mest ut fra nettverksmodellen. Det gir videre mening å snakke om forskjellige grader av verdi i disse modellene. I en hierarkisk modell har det øverste ledd den høyeste verdi, og mest makt, mens i den vertikale modell er det den sentrale tekstdel, eller det sentrale mål, som er mest verdifull, og som de andre deler skal understøtte.
Ved å fokusere på verdi og sentralstyring kommer man inn på de sentrale forskjellene mellom de sentralstyrte modellene og nettverksmodellen.
Nettverksmodellen er den minst lineære topografien. I et nettverk har man ingen start, ingen ende og intet sentrum. Fordelen er at dette er svært fleksibelt, lett å utvide med flere ledd eller noder, og samtidig et sterkt system. Bakdelen er at alle deler har like stor verdi, og at det følgelig er vanskelig å koordinere funksjoner og fokusere ressurser.
Innenfor formidling kan en spesifikk oppgave være å styre lesningen, eller tilby en foretrukket lesning av en tekst. Et mål innholdsprodusenter i alle medier vil kjenne seg igjen i. Å presentere en tekst i en modell uten start, ende eller sentrum, og hvor alle deler er like viktige bryter med de fleste prinsipper innenfor fortellerteori, og man risikerer at teksten fremstår som et kaos heller enn en meningsfull tekst.
Grunnet dette har informasjonsorganisering og formidling innenfor webmediet stort sett nyttet seg av de sentralstyrte modellene, til tross for at Internett som helhet bygger på en veldig eksplisitt nettverksmodell, som jeg vil gå videre med å vise.
1.2
Internetts historie, og webmediets konseptuelle bakgrunn.
Hvordan Internett oppsto på slutten av 60-tallet som en koalisjon mellom militære og akademiske krefter er i dag både velkjent og veldokumentert [1]. En kort oppsummering er likevel på plass, da det gir oss et godt bilde av nettverksmodellens styrker, og da det plasserer webmediet i en kontekst.
Bakgrunnen til Internett finner man i ARPANET, et nettverk satt opp av ARPA [2] i 1969. Da ingen teknologi oppstår i et vakuum, er dette heller ikke tilfellet for Internett; ARPA oppsto grunnet den politiske situasjon og det politiske klima på den tiden -opprustningskappløpet mellom den vestlige og den østlige verden, den kalde krigen hvor USA og Sovjet var de sentrale aktører (Castells 2001: 10).
Målet for ARPA var å mobilisere forskningsressurser, spesielt fra akademia, for å kunne utvikle militær overlegenhet over Sovjet. En del av forskningen gikk på å utvikle et desentralisert og fleksibelt kommunikasjonssystem som kunne overleve et atomangrep. Dette var en liten del av ARPAs forskning, men her finner vi spiren til det vi i dag kjenner som Internett.
Det ble forsket på en lang rekke ting i ARPA, men en av de viktigste nyvinningene, og det som skulle bli grunnstenen i det nye kommunikasjonssystemet, var pakkeswitching (packet switching) utviklet av Paul Baran og Donald Davies. Pakkeswitching er basert på en teknologi der man deler opp data i mindre biter og hvor hver pakke er utstyrt med en adresse, som så kan sendes fra a til b. Når en pakke blir mottatt i den andre enden blir pakkene satt sammen igjen i riktig rekkefølge.
På denne måten skapte man et kommunikasjonssystem basert på et nettverksmodell, og unngikk på den måten å skape et system som kan slås ut ved å ramme toppen av hierarkiet. Ingen av enkeltkomponentene var viktigere enn andre, og for å slå ut systemet måtte man derfor slå ut alle enkeltkomponentene.
Denne teknologien ble basis for hvordan ARPANET fungerte, og er fortsatt basis for hvordan Internett fungerer i dag. Mange forskjellige pakkeswitchingsteknologier har vært i bruk i netthistorien, men Internett har siden 1978 kjørt på TCP/IP [3] – den mest stabile og tilpasningsdyktige av de protokoller som ble utviklet.
Pakkeswitching er sentralt i netthistorien da dette er teknologien som muliggjør nettverksmodellen i internettsammenheng, og samtidig muliggjør at flere nettverk, basert på forskjellig teknologi, og med forskjellige bruksområder, kan kommunisere med hverandre over en felles kommunikasjonsprotokoll. Man kan ha et nettverk av nettverk.
Den første noden i nettverket utenfor ARPANET ble UCLAs Network Measurement Center i 1969, og etter dette gikk utviklingen hurtig. Flere og flere nettverk ble knyttet til, først og fremst universiteter og læringsanstalter, men senere også private og kommersielle nettverker. I 1997 var det tilknyttet 134.365 nettverk som tilsammen utgjorde det vi kaller for Internett [4].
World Wide Web – her, og i resten av oppgaven, henvist til som “web” eller “webmediet” – er ett av disse 134.000 nett som i dag kommuniserer over TCP/IP (ibid 2001: 10-23).
Skal man spore webmediets historie er det sentralt å se på et av dets mest fremtredende kjennetegn, nemlig hypertekst og hypertekstens historie. Det konseptuelle tankegodt som ligger til grunn for dette kan spores flere plasser.
I 1945 utga Vannvar Bush sin ofte siterte artikkel “As we may think”, regnet som det første banebrytende verk på området. Begrepet hypertekst ble imidlertid først brukt av Ted Nelson i 60-årene, kjent for sitt Xanadu-system – et system hvor den ikke-lineære struktur for presentasjon av data er sentral. I 60-årene var også forskeren Douglas Engelbart sentral, som blant annet skapte den første velfungerende node. Og på slutten av 80-tallet ble HyperCard, utviklet av Bill Atkinson, implementert i Apples Mac. HyperCard var et system som gjorde det mulig å benytte en grafisk brukergrenseflate til å aktivisere linker mellom forskjellige dokumenter, og var for mange det første møtet med hypertekst og hypermedier (Toscan i Jensen 1998).
Flere skal altså ha æren for at vi har kommet dit vi er i dag. Jeg vil imidlertid dvele litt med Vannevar Bush, og hans idéer om Memexen som presentert i “As we may think”. I artikkelen angrep Bush den hierarkiske eller indeksive metoden man da brukte for å lagre og sortere dokumenter, og hevdet denne stemte dårlig overens med den mer assosiative måten mennesker tenker på. Bush hevdet man burde utnytte det assosiative aspektet, og den viten man hadde om hvordan hjernen fungerer i fremtidige lagringsmedier, og lanserte idéen om Memexen – en maskin for assosiativ arkivering og sortering av data (Bush i Trend: 2001).
Memexen ble aldri en realitet, men tankene om assosiativ arkivering ble videreført til web, et nettverk bygget opp av hypertekst, hvor koblingene mellom data kan være langt mer assosiative enn indeksive. Ved eksponering av en websides data kan vi ved å følge linker bli eksponert for flere typer lignende data. Dette er grunntanken i hypertekst, og hvordan linker fungerer på web.
Men det var ikke bare idéen om assosiativ arkivering i Memexen som presederte web. Memexen var basert på et standardformat for data, nemlig mikrofilm. Hvert innlegg i Memexen fikk sin egen, unike adresse. Memexen var utstyrt med en tilbake-knapp for å bla tilbake i systemet, og hadde i tillegg mulighet for å prosjektere flere stykker data samtidig.
På web er standardformatet HTML [5], et språk som definerer hva som er hva i en webside. Eksempelvis kan det si hva som er en overskrift, hva som er en tekstblokk, hva som er en tabell etc. I tillegg har hver webside en egen, unik adresse, en URL [6]. Videre er den mest kjente funksjonen i dagens weblesere (browsere) back-knappen [7], som brukes for å bla tilbake i systemet. Ved å åpne flere weblesere kan man prosjektere flere stykker data samtidig. Vi ser altså svært mange likhetstrekk mellom idéene om Memexen og hvordan web fungerer i dag.
Den så langt siste viktige person i utviklingen av hyperteksten er Tim Berners-Lee, mannen som skapte web og hvis system gjorde hypertekst til allemannseie. Interessant nok kjente ikke Berners-Lee til Vannevar Bush sine tanker da han i 1990 brakte idéene bak Memexen til en realitet. Berners-Lee arbeidet på den tiden ved CERN, det europeiske laboratoriet for partikkelfysikk, og brukte deler av arbeidstiden på å videreutvikle et program han hadde utviklet i 1980, kalt Enquire. Ved hjelp av utstrakt støtte fra open-source-miljøet utviklet, definerte og implementerte han HTTP [8], HTML og URL, som den dag i dag er de tekniske grunnpilarene for web. På grunn av den åpne protokollen TCP/IP ble World Wide Web en del av Internett i 1991, og har siden da vært det enkeltnettverk de fleste forbinder med Internett, ved siden av e-post. (Castells 2001: 28).
Berner-Lees programvare ble distribuert som open-source på Usenet i 1991, og utviklere over hele verden begynte straks å videreutvikle programvaren. Flere weblesere ble utviklet, men det var først da Mosaic, utviklet av Marc Andreessen, ble postet på Usenet i 1993 man begynte å se konturene av hva web kunne bli for noe. Mosaic hadde til forskjell fra tidligere weblesere mulighet for å distribuere grafikk over nettet. Og Mosaic, som senere ble til Netscape, ble den første suksesshistorien på web (ibid: 16).
Jeg har her tatt for meg Internetts overordnede historie, og fokusert på hvordan nettverksmodellen brukt her fungerer i praksis ved hjelp av pakkeswitching. En nettverksmodell, hvor alle deler var like verdifulle, ble løsningen på det problem det amerikanske militæret hadde med sine tidligere kommunikasjonssystemer – at de kunne slås ut ved å ramme kjernen i systemet.
Jeg tok videre for meg det konseptuelle tankegodt som lå bak web, med fokus på hypertekst. Også her skulle et problem løses, nemlig problemet med den sentralstyrte metoden man da brukte til å lagre, sortere og finne informasjon. Og også her ble en modell tettere opp mot nettverksmodellen benyttet.
Mye mer kan sies, men da fokus her ikke er det rent historiske har det vært nødvendig å foreta visse avgrensninger. Det sentrale er at hvor nettverksmodellen ble ansett som en løsning på informasjonsorganisering ved hjelp av hypertekst, har de problemene modellen fører med seg ført til at de fleste websteder har vært bygd opp på bakgrunn av mer sentralstyrte modeller. Jeg vil nå gå mer konkret til verks, og ta for meg noe av den evolusjon webmediet har gått igjennom i de årene det har eksistert, da dette gir et mer oppdatert bilde av hvor webmediet står i dag, modeller som har vært brukt til formidling og organisasjon, og gir en god bakgrunn å ha med videre i oppgaven.
1.3
Evolusjonen av websteder.
“Hard to believe, but corporate Web sites have been around for over 10 years now. It’s fascinating to see how they have evolved over the years, from the early days of magazine-style brochureware to the most recent trends of two-way Web interfaces.”
– Richard MacManus: 2004
Skal man angripe evolusjonen av websteder er det mange problemer man støter på. Det er skrevet lite om det, og de fleste websteder som eksisterte for ti år siden eksisterer ikke i samme form i dag, noe som gjør det vanskelig å foreta en komparativ analyse.
Jeg har derfor valgt å støtte meg til en populærvitenskapelig artikkel som ser på historien fra en utviklers ståsted. Richard MacManus identifiserer i sin artikkel “The Evolution of Corporate Websites” [9] tre megaperioder vi har gått gjennom, og ser på hvordan forskjellige bruker- og pressgrupper så vel som utviklingen av ny teknologi har satt sitt spor på hver av periodene.
Den første perioden MacManus identifiserer er de tidlige årene fra 1993 til 1996, hvor web gikk fra å være et medie forskere brukte til å formidle data, til å bli et medie også den kommersielle verden interesserte seg for. Med utviklingen av nye weblesere og webleserteknologier oppdaget først designere mediet, og web ble det nye domenet for eksperimentering med design. I forlengelsen av dette begynte også markedføringsbransjen å interessere seg for det kommersielle potensialet til web. Men hvordan skulle man legge opp formidlingen i det nye mediet?
Mange av de tidlige webstedet, og ikke minst den tidlige akademiske litteraturen fokuserte på nettet og web som et helt eget sted – populært beskrevet som cyberspace. MacManus viser til Pepsi og Coca-Cola sine websteder, og de mål de hadde for å lage virtuelle verdener:
“It was a broadcasting mentality, but they also recognized that the Web was an interactive medium. Pepsi.com provided a ‘destination’ for consumers to ‘play’ and ‘hang out’.”
(ibid: 2)
Å se på websteder som et sted å være fortsatte inn i den andre store perioden MacManus identifiserer, fra 1997-1999. Amazon fremstilte seg selv først som en “virtuell bokhandel”, men på denne tiden begynte man i tillegg å se på web som en potensiell markedsplass hvor man kunne selge og kjøpe varer.
Metaforer er en god metode for å gjøre det ukjente kjent, og ved å se på hvordan man bruker metaforer i en historisk periode kan man få et innblikk i hvordan man tenkte den gang. På denne tiden i webhistorien ble en rekke metaforer fra den virkelige verden brukt på websteder. Man brukte bymetaforer, shoppingsenter-metaforer, hjemme- og rom-metaforer for å beskrive og utforme websteder. En morsom og illustrerende ting er å se på de ikoner som var vidt utbredt for å vise at et websted var under utbygging (“under construction”) tidligere – gateskilt, arbeidere, gravemaskiner etc [10].
Det samme kan vi se på de metaforer brukt om menneskene som nyttet webmediet på den tiden. Den gang var de ofte beskrevet som et publikum eller tilskuere mens vi i dag ser på dem som aktive brukere. MacManus henviser til push-bølgen i 1997 som kuliminasjonen av denne tankegangen. Tankegangen bak push var at brukere skulle få tilsendt informasjon direkte på gitte tidspunkt heller enn å konsultere den selv, en tankegang hentet fra transmisjonsmedier som radio og tv.
Push var stort på denne tiden, og i bransjebladene var det generell konsensus om at dette var eneste vei fremover. Bransjebibelen Wired proklamerte med frasen “kiss your browser goodbye” [11]at webleserens tid var over. Også her er det interessant å se på metaforene brukt innen push-teknologi. Pointcast var markedsleder, Nescape hadde sin Netcaster, mens Microsoft opererte med begrepene Active Channels og Webcaster – metaforer direkte hentet fra transmisjonsmediene (Sommerseth og Almendingen 1998: kap. 2, side 2).
Den så langt siste perioden MacManus identifiserer er den fra 2000 og opp til i dag. Starten av denne perioden var preget av at websteder ble mer fokusert på å være transaksjonelle enn bare interaktive, man skulle også kunne bruke dem til noe. Databaser og content-managing systemer (CMS) ble basis for de fleste websteder, som gjorde databehandling og personalisering mye lettere og mer avansert enn det hadde vært til da.
En annen stor trend innenfor webutviklingen i denne perioden har vært standardisering og spesialisering. Man er nå i kjølvannet av dotcom-kræsjet, og mye grunnet de fiaskoer man opplevde i dotcom-tiden kan man identifisere et fokusskift. Fra å ha en (svært urealistisk) tro på at alle kunne lykkes på web så lenge man hadde et websted, ble fokus mer rettet mot tradisjonelle prinsipper for forretningsdrift; å skape gode, verdifulle og brukervennlige produkter, og man innså at det å lykkes på web også krevde hardt arbeid.
Jakob Nielsen ble nærmest et ikon innenfor brukervennlighet, og i bransjen hvor designere og markedsføringsbransjen hadde hatt stor innflytelse oppsto nå en rekke mer spesialiserte profesjoner i tillegg, fra informasjonsdesign, informasjonsarkitektur, interaksjonsdesign, brukervennlighet, tilgjengelighet etc. Forskjellige profesjoner, men med det felles at de alle søker å gi et websted merverdi på forskjellige måter.
På samme tid har de webstandarder som anbefalt av W3C [12] fått større oppmerksomhet enn før. XML [13] er et av de største buzzord i bransjen i dag, og etter at W3C annonserte XHTML 1.0 [14] og CSS [15] som foretrukte standarder i 2000 – forløperene til XML – har både utviklere av websteder og utviklere av weblesere, hvor spesielt sistnevnte tradisjonelt har vært svært motvillige, også begynt å støtte disse standarder i en mye større grad enn før
Man skal være forsiktig med å trekke konklusjoner fra artiker som dette, men artikkelen illustrerer på en god måte en utvikling man har sett. I dag bruker man ikke metaforer som publikum eller tilskuere lengre, og det er en bedre forståelse for webmediet som et unikt medie. Og det ville virket merkelig om Amazon fremstilte seg selv som en virtuell bokhandel. Webmediet har gått fra å være et medie sterkt influert av designere og markedsføringsbransjen, med statiske og hierarkiste websteder til å bli et mer dynamisk medie, styrt av avanserte databaser og CMS-er. Og man har et medie hvor det i dag finnes en rekke spesialiserte profesjoner.
Jeg har over gått gjennom hvilke forskjellige prinsipper man har for organisering både generelt og for hypertekst spesielt. Jeg har tatt for meg historien til Internett og historien og konseptet bak webmediet, og videre belyst noen utviklingstrekk vi har sett i webmediet.
Et sentralt poeng er at hvor Internett som helhet er basert på, og fungerer på grunn av, nettverksmodellen, har dette ikke i like stor grad vært tilfellet for informasjonsorganisering i webmediet. Jeg mener imidlertid dette er i ferd med å endre seg, og for å belyse dette vil jeg nå ta for meg noen sentrale fenomener og suksesshistorier som har oppstått på web. Noe som ligger i forlengelsen av de utviklingstrekk jeg har beskrevet over.
En av de viktigste trendene vi ser på web i dag er inntoget og viktigheten av søkemaskiner, og det er derfor søkemaskiner jeg vil ta for meg først. Google er en av internettverdenens største suksesshistorier, de befinner seg i en interessant posisjon i dag, og står for en rekke nyvinninger og suksessfull eksperimentering med mediet og vil derfor tjene som sentralt case i neste del av oppgaven.
Del 2
2.1
Vår tilgang til medier, tidlige organiseringsmodeller og tidlige søkemaskiner.
Før jeg går i dybden med søkemaskiner kan det være nyttig å ta et steg tilbake, og se på hvordan webmediet fundamentalt skiller seg fra andre medier med tanke på hvordan vi får tilgang til informasjon. For å gjøre dette kan man ta utgangspunkt i Bordewijk og Kaams klassiske modell for klassifisering av informasjonstjenester basert på to variabler: hvem som produserer informasjon og hvem som distribuerer den. Ut fra disse trekkes fire idealtyper opp, som ses i tabellen under.
| Informasjon produsert av senter | Informasjon produsert av bruker | |
| Distribusjon kontrollert av senter | Transmisjon | Registrering |
| Distribusjon kontrollert av bruker | Konsultasjon | Konversasjon |
(Tabellen hentet fra Bordewijk og Kaam 1986: 16-20, min oversettelse)
Tabellen er i høy grad selvforklarende. Hvis et senter produserer informasjon / innhold, men brukeren ikke har kontroll over hvordan og når den blir distribuert er det snakk om transmisjon. Tv og radio er transmisjonmedier. Innhold blir produsert, og distribuert på bestemte tidspunkt. På den andre siden, hvis et senter produserer innhold men brukeren selv bestemmer når han / hun skal se det er det snakk om konsultasjon.
Hvor denne forskjellen med første øyekast kan virke basal vil jeg hevde den er sentral for å finne kjernen i de forskjellige mediene, i hvordan de blir brukt og hvordan de blir oppfattet. Jeg nevnte push-bølgen i 1996 / 1997 som et eksempel på at webmediet tok tankeganger fra andre kjente medier, noe som den gang ikke fungerte [16].
Webmediet er kanskje det reneste konsultasjonsmedie vi har, av flere grunner. En ting er at brukeren selv bestemmer når han / hun vil ha tilgang til informasjonen, og er derfor frigjort fra transmisjonsmedienes utsendelsesskjema. På denne måten havner webmediet klart i Bordewijk og Kaams rubrikk for konsultasjon.
En annen faktor som gjør at webmediet skiller seg fundamentalt fra andre medier, og som gjør konsultasjon og konsultasjonsmekaniser enda mer sentrale er mengden informasjon. Det finnes milliarder av websider i dag, og man har teoretisk sett tilgang til alt om man først har tilgang til Internett. Det er en informasjonsoverflod.
Informasjonsoverflod har alltid vært et problem på web, og derfor har det alltid vært sentralt å finne gode måter å navigere og finne informasjon på – eller gode mekanismer for konsultasjon. I forlengelsen av dette har det alltid vært aktører på web som har ønsket å tilby disse mekanismene. De forskjellige strategier man har brukt for dette er hva jeg vil gå videre med nå.
I de tidlige dager på web var indekser den foretrukte modell for å organisere informasjon. Yahoo! var et av de første store webstedene, og besto den gang kun av en indeks – en hierarkisk organisert samling av linker, oppdelt i kategorier og underkategorier, og en vidt kopiert modell [17].
Indekser er sentralstyrte systemer, og bygger på en hierarkisk organiseringsmodell. Som jeg var inne på tidligere har dette den fordel at avsender kan styre lesningen av sin tekst på en bedre måte. Det er mennesker som samler, vurderer og organiserer linker, og dette kan fungere som en garanti på at man får opplistet de mest sentrale websteder i hver kategori, som gir avsender en høy grad av kontroll.
En annen men lignende trend på slutten av 90-tallet var innholdsportaler, ofte kjent som startsider – sider med det mål for øye å være en brukers utgangspunkt til alt av nyheter og ting av interesse på web. På samme måte som indekser har innholdsportaler den fordel at avsender har en høy grad av kontroll over innholdet. Bakdelen ved begge er at det er svært ressurskrevende å produsere innhold, og at informasjonsvolumet så vel som konkurransen er enorm. En innholdsportal krever til en viss grad egne journalister som produserer innhold, mens indekser krever at det er ansatt mennesker for å gå gjennom, vurdere og indeksere ressurser. Som et eksempel kan det nevnes at Jubii i København hadde nærmere 20 bibliotekarer ansatt for å indeksers websteder da de toppet i 1999 / 2000. I dag har de 2-4 [18].
Selv om både indekser og startsiden fortsatt eksisterer i dag, og sannsynligvis vil fortsette å eksistere i lang tid fremover, ble det opplagt at denne modellen for å samle og presentere innhold ikke ville være optimal i lengden, grunnet det store arbeid det er å produsere innhold og manuelt indeksere innhold. Produsenter begynte å se etter andre løsninger, og fant det i søkemaskiner, noe som alltid har eksistert på nettet i større eller mindre grad.
Inntoget av de mer profesjonelle søkemaskiner gjør at man som smått kan begynne å snakke om en overgang mellom en sentralstyrt strategi til en en nettverksbasert strategi for å organisere store mengder informasjon. Søkemaskiner har ikke egenproduksjon selv, på samme måte som indekser og startsider, men bruker teknologi for å indeksere, behandle og presentere andres innhold automatisk.
Men om søkemaskiner var løsningen presenterte det også nye problemer. Problemet med nettverksmodellen er blant annet at alle enheter har like stor, eller like liten verdi, så hvordan finne de mest relevante treff fra en massiv mengde data, og presentere dem først? Dette var (og er) et sentralt problem med søkemaskiner, og tidlige søkemaskiner hadde store problemer med å plassere søkeresultat i forhold til hverandre, der de mest relevante ble presentert før de mindre relevante. Den kontrollen avsender hadde over teksten ved å nytte de sentralstyrte modellene for å styre lesning forsvant.
For å forstå dette bedre kan det være interessant å se på hvilke elementer som inngår i en søkemaskin, som basalt består av tre elementer. I første ledd går søkemaskinen ut og besøker websteder, og følger lenker fra webside til webside. All data som finnes ved hjelp av disse besøk havner i søkemaskinens database, eller katalog. Eventuelle endringer i katalogen blir så oppdatert neste gang søkemaskinen besøker websteder. Dette er ingen enkel oppgave, og krever mange ressurser, men det er likevel en liten oppgave i forhold til å få presentert disse data på en fornuftig måte.
Det siste og viktigste element er derfor søkemaskinprogramvaren. Programvarens oppgave er å vektlegge de data som finnes i katalogen på best mulig måte, og på den måten finne de mest relevante sider å presentere til brukeren [19].
Tidlige søkemaskiner som AltaVista, Lycos og Hotbot var bygget på relativt primitive algoritmer, og vektla ofte elementer som ikke nødvendigvis ga brukeren mest relevante resultater. Blant annet vektla de metainformasjon som spesifisert i meta-tagger i HTML-dokumenter – informasjon usynlig for brukeren, men synlig for søkemaskinene [20]. Dette ble imidlertid massivt misbrukt av eiere av websteder, som kunne legge inn (irrelevant) informasjon i metatagger, og på den måten få høyere plassering i søkemotorer. En annen populær strategi var å skrive typiske søkeord i dokumentene, men med samme tekstfarge som bakgrunnsfarge, så søkeordene ikke umiddelbart var synlige for brukere, men likevel ville bli fanget opp av søkemotorene.
På denne tiden kom det samtidig en mengde artikler om søketips, der brukere ble oppfordret til å spesifisere søkene bedre, bruke boleanske metoder, bruke “+”, “-” og “*” foran, etter og mellom søkeord for å indikere bedre til søkemaskinen hva slags informasjon man var ute etter [21]. Det å kunne søke ble sentralt for å kunne få de mest relevante resultater.
Kort sagt, de tidlige søkemotorer krevde mye av brukerne for å gi relevante resultater, og de var lette å manipulere, noe som i siste instans førte til at brukerene ikke fikk de mest relevante resultater. I 1998 skjedde det imidlertid noe interessant, da søkemaskinen Google så dagens lys.
2.2
Google Incorporated oppstår.
“On September 7, 1998, Google Inc. opened its door in Menlo Park, California. The door came with a remote control, as it was attached to the garage of a friend who sublet space to the new corporations staff of three. The office offered several big advantages, including a washer and dryer and a hot tub.”
– Fra Google Corporate Information: Google History [22].
Historien om Google er på mange måter en klassisk “rags to riches”-historie. I 1995 møttes informatikkstudentene Larry Page og Sergey Brin på Stanford University i California. Etterfølgende år begynte de å samarbeide om en søkemotor kalt BackRub, et navn den hadde fått grunnet sin unike måte å analysere lenker som pekte tilbake på en gitt webside (“back links”). Her så man starten på hva som i dag er kjent som Pagerank, Googles analyseringsalgoritme som bestemmer et websteds relative plassering blant andre websteder i samme sjanger.
Page og Brin ville i utgangspunktet selge sin teknologi til en tredjepart heller enn å starte for seg selv, men få av de store aktører i bransjen på den tiden viste noen interesse, og de ble anbefalt å likevel starte opp selv. Etter flere startproblemer fikk de til slutt sin første investor i Andy Bechtolsheim, en av hjernene bak Sun Microsystems. Han skrev ut en sjekk på 100.000 dollar til Google Inc., et selskap som da ikke fantes, men ble opprettet som følge av Bechtolsheims investering. Google Incorporated var nå en realitet.
På denne tiden serverte Google 10.000 søk daglig, og begynte som smått å få pressedekning i bransjeblader og -magasiner. I 1999 ble Red Hat, en av verdens største tilbydere av open-source-teknologi, Googles første kommersielle søkekunde, og senere samme år annonserte Google Inc. at de hadde sikret seg 25 millioner dollar i videre midler fra to av Silicon Valleys største investeringsfirmaer. Google serverte nå over 500.000 søk daglig.
Resten er historie, Google inngikk samarbeidsavtaler med datidens giganter som AOL / Netscape og Yahoo!, i tillegg til en rekke store nasjonale og internasjonale portaler, som gjorde sitt for at Google i 1999 serverte over 3.000.000 søk daglig. Firmaet fikk en rekke priser og utmerkelser for sin søkemaskin og sin teknologi, og Google var snart på alles lepper (ibid).
I 2004 er søk den nye store kamparenaen på web. Yahoo! har sagt opp sitt tidligere samarbeid med Google for heller å bli en konkurrent, Microsoft har annonsert at de vil inkludere søk som en integrert del av sitt nye operativsystem Longhorn, forventet i 2006, og Amazon har lansert sin egen søkemotor [23] som kombinerer Google-søk med egne produktsøk. Det ligger enormt mange penger i betalte annonser og søkeplasseringer på søkemotorer, og i kontekstdrevne annonser basert på søkeresultater.
I 2004 ble Google utropt til “brand of the year” for andre år på rad av, “å google” har blitt et uttrykk – egennavnet har blitt et verb. De indekserer over 4.3 milliarder sider, og er uten tvil den største inngang til informasjon på web som finnes.
Hva er det som har gjort dette? Det finnes flere årsaker, men en kjerneårsak er at Google har klart å gi sine brukere mer relevante søkeresultater enn konkurrentene klarte. Dette har de gjort ved å overkomme noen sentrale problemer med nettverksmodellen som styringsprinsipp, nemlig å kunne gi noen resultater høyere verdi enn andre.
2.3
Pagerank.
“PageRank relies on the uniquely democratic nature of the web by using its vast link structure as an indicator of an individual page’s value.”
– Fra Googles hjemmeside [24]
Som tidligere nevnt er et fundamentalt problem med nettverksmodellen det samme som er dens største styrke. Modellen er svært sterk, tilpasningsdyktig og lett å utvide, men kan være kaotisk når man skal bruke modellen til å organisere informasjon. Det er søkemaskinprogramvarens jobb å vektlegge de forskjellige dokumentene søkemaskinen har i katalogen sin relativt i forhold til hverandre.
Tradisjonelt vektet søkemaskiner først og fremst etter et prinsipp basert på lokasjon og frekvens. Men dette menes at søkeord lokalisert prominent i dokumener, som i tittel eller overskrifter blir vektet høyere enn søkeord plassert på mindre prominente plasser. I tillegg vektes det høyere hvis søkeord blir gjentatt mange ganger i dokumentet [25]. Problemet med dette er at det er forholdsvis lett å manipulere, som også ble gjort i stor skala tidligere.
Det er en rekke forskjellige teknikker og metodikker som inngår i en søkemaskins behandling av sin katalog, og hvordan det eksakt foregår er høyt beskyttede forretningshemmeligeter hos alle søkemaskinoperatører. Lokasjon og frekvens er fortsatt viktig, men Google har i tillegg sin egen algoritme, Pagerank.
Pagerank er en numerisk verdi som representerer hvor viktig en side er på web, og som sitatet over antyder er det en teknikk som støtter seg mye til linkanalyse, det Google opprinnelig ble kjent for da søkemaskinen fortsatt gikk under navnet BackRub. I praksis fungerer pagerank på den måte at hvis en webside har en link til en annen webside, så fungerer denne utgående linken som en stemme til den andre siden. Jo flere stemmer eller inngående linker en webside har, jo viktigere blir den antatt å være. I tillegg påvirker den stemmegivende websides pagerank også verdien av stemmen den gir fra seg. Sagt på en annen måte: hvis et websted Google anser for å være viktig tilbyr en link til et websted har den linken mer å si enn en tilsvarende link fra et websted Google ikke anser for å være så viktig [26].
Logikken bak er enkel: hvis flere websteder linker til et bestemt websted er det grunn til å tro at dette webstedet er populært blant lesere, og en ressurs innen sitt felt. En hypotese som også har vist seg å holde stikk i praksis.
Pagerank er bare én blant mange metoder som brukes til å rangere søkeresultater, men en svært viktig metode. Det som skiller Pagerank mest ut fra andre metoder er at Pagerank tar utgangspunkt i nettverket selv, og bruker nettverket som en ressurs for å vekte søkeresultater opp mot hverandre – nettverket blir selv garantisten for relevante søkeresultater.
Jeg kommer tilbake til dette i oppsummeringen av del to, men først ønsker jeg å se på en annen av Googles kjernetjenester, nemlig annonser, hvor de også bruker nettverksmodellen for organisering og presentasjon.
2.4
Annonser på web – AdWords og AdSense.
“Google, once simply the world’s best search engine, is fast reinventing itself as an advertising company.”
– Wired Magazine, mars 2004 [27].
Webmediet har alltid hatt en utbredt gratiskultur, hvor man har forventet at innhold er gratis. Bant annet grunnet uvilligheten til å betale har annonser vidt blitt sett på som den primære inntjeningsmulighet på web [28].
Man finner flere typer av reklamer på web, men tradisjonelt har man snakket om bannerannonser og pop-up-annonser. Felles for disse har vært at man ved å klikke på en annonse på et websted har blitt ført videre til annonsørens websted. Annonsøren har betalt en viss sum for hver person som har blitt ført gjennom fra en annonse, noe vi kjenner som cost-per-click (CPC) [29]. En annonses suksess har videre blitt bedømt etter dens click-through-rate (CTR) [30], et gjennomsnittsnummer av antallet brukere som har klikket annonsen etter å ha blitt presentert for den, uttrykt som prosent.
Problemene med denne modellen har vært mange. Et problem har vært at man ikke har hatt ressurser til å målrette reklamene så godt som man gjerne har ønsket – et sentralt mål for all markedsføring. Å presentere reklamer på en webside relatert til det innhold man har på websiden har vært et problem for websteder uten et spesialisert tema. Eksempelvis på nettaviser som har mye innhold, men om en rekke forskjellige tema. Et annet problem relaterer seg til mediet som et konsultasjonsmedie: man bruker web målrettet til å finne konkret informasjon, og lar seg derfor ikke så lett distrahere.
Disse og andre grunner førte til at Jakob Nielsen allerede i 1997 proklamerte at annonsering ikke fungerte på web, da click-through-rate ofte var så lav som 0.5% [31].
Google tilbyr to forskjellige annonseringsmetoder. Den første er AdWords, tekstannonser presentert i Googles opplisting av søkeresultater. Disse annonsene blir presentert på bakgrunn av hvilke søkeord en bruker søker etter, og er en teknikk som har vist seg å ha stor suksess. Wired melder i 2004 at click-through-rate på disse er opp mot 15% [32], distinkt mer enn tradisjonelle annonser, og selv Jakob Nielsen har utrykt sin begeistring for disse annonsene [33]. En hovedgrunn er at søkemaskiner er de eneste websteder brukere kommer til kun for å finne annen informasjon, og så gå videre. I tillegg vet søkemaskinene eksakt hvilke søkeord brukerne nytter, og kan derfor målrette annonser mye lettere.
Mer sentralt for denne oppgavens tema er imidlertid Googles utvidelse av AdWords, nemlig AdSense. AdSense er de samme annonsene som AdWords men skiller seg ut da dette er annonser som presenteres på tredjeparts websteder – mer likt tradisjonelle bannerreklamer. Alle websteder som oppfyller kriteriene til AdSense kan delta, og programmet fungerer slik at Google betaler webstedeieren for hvert treff annonsen gir (som igjen blir betalt av den opprinnelig annonsøren).
Hvor et av problememe med annonser på web som nevnt har vært arbeidet med å målrette dem, klarer AdSense dette automatisk ved å nytte de samme algoritmer som søkemaskinen bruker, blant annet den linkanalyse som ligger til grunn for Pagerank. Google analyserer en sides innhold bl.a. basert på hvilke ord som inngår, hvilke linker som fører til siden og hvilke linker som fører ut fra siden. På denne måten klarer Google å skape en relativt presis forståelse av innholdet på siden, og serverer ut sine annonser basert på denne forståelsen.
Har du eksempelvis en side hvor innholdet handler om klassiske forfattere, vil AdSense typisk servere annonser hvor du kan kjøpe bøker av klassiske forfattere, og andre ting relatert til klassike forfattere og litteratur [34].
Siden AdSense presenteres på andre sider enn søkemotorens er click-through-rate noe lavere enn de 15% nevnt over, men likevel melder Wired om betraktelig høyere click-through-rate enn for almindelige bannerannonser, og i dag finner man AdSense flere og flere store websteder, som CNN, New York Times og Amazon, i tillegg til en rekke andre store innholdsleverandører og en mengde av de mest popoulære weblogs.
Det sentrale med AdWords og AdSense er imidlertid at Google ved hjelp av nettverksanalyse og den teknologi som ligger bak pagerank har klart å automatisere plasseringen av annonser på websteder, og skape kontekstrelevante annonser – som (naturlig nok) har vist seg å være mer effektive enn de tradisjonelle bannerannnonser.
Annonser kan nå segmentstyres og tilrettelegges etter innhold med et minimum av manuell innvirkning, og Google har igjen klart å bruke nettverksmodellen til å utføre oppgaver som tidligere hadde krevd en større grad av sentralstyring. Dette er videre viktig da disse annonser er en av Googles viktigste inntektskilder, og da annonsemodellen fortsatt er den mest utbredte muligheten man har til å tjene penger på websteder fokusert på innhold.
2.5
Oppsummering.
Jeg har i de to underkapitlene over gått gjennom Pagerank som metode for å vekte søkeresultater opp mot hverandre, og videre gjennom Googles annonseringsmetodikker AdWords og AdSense.
Google har utvilsomt gjort mye riktig, og det er dette jeg har fokusert på i denne delen av oppgaven. Likevel er det viktig å ikke se seg blind på hva de har gjort, og ikke anse Googles metode som fasit. Google er i dag, som de tidlige søkemaskiner var før, utsatt for en rekke manipuleringsforsøk, hvor aktører bruker forskjellige mekanismer for å gi websteder falsk Pagerank og dermed manipulere disse høyere opp i søkeresultatene. Søkemaskinoptimering en større bransje nå enn det noensinne har vært, og jeg kjenner personlig til 4-5 firma i København alene som driver med dette. Google straffer manipulering av søkeresultater hardt, og har generelt gode systemer for å forebygge dette, men hvordan de takler manipulering i fremtiden, og hvordan Pagerank vil utvikle seg generelt er essensielt for Googles videre suksess.
På samme måte er det ingen garanti for at tekstannonsene i AdWords og AdSense ikke kan lide samme skjebne som de tradisjonelle bannerannonsene. AdSense blir brukt mer og mer i dag, og nyter stor suksess i forhold til andre annonser, men dette kan være grunnet nyhetens interesse. Det er grunner til å tro at den “banner-blindness” [35] man kjenner fra tradisjonelle bannerannonser også vil bli mer og mer gjeldende for tekstannonser.
Det sentrale med hva Google har gjort her, er imidlertid at de har klart å kombinere nettverksmodellen styrker med de sentralstyrte modellers styrker. Ved å automatisk innhente, analysere og behandle data har Google indeksert over 4.3 milliarder websider, noe som i praksis hadde vært umulig hvis man skulle benytte manuell innhenting og behandling som de tidlige indekser gjorde.
Ved å ta utgangspunkt i nettverket selv, og analysere hvordan de forskjellige delene av nettverket forholder seg til hverandre har Google ved hjelp av Pagerank klart å tilføre nettverksmodellen noe nytt og verdifult nettopp ved å kunne tillegge forskjellig verdi til de forskjellige bestanddeler, uten å gå på kompromiss med modellens styrker. Pagerank gjør at nettverksmodellen kan kombinere sine største styrker med de største styrker til de sentralstyrte modellene.
På denne måten har Google klart å få en unik posisjon som verdens definitivt ledende aktør innenfor søk på nettet. I tillegg har de tilført noe nytt og verdifullt til annonsemarkedet i webmediet, ved å utvide den teknologi de har brukt for nettverksanalyse og intern presentasjon og organisasjon til også å kunne virke på tredjeparts sider – et program som har hatt stor suksess og i dag bidrar til det meste av Googles inntjening.
Jeg har i denne delen av oppgaven fokusert på hvordan Google har brukt nettverksmodellen som en basis for å presentere sine søkeresultater og annonser både på egne sider og på tredjeparts websteder, og hvordan de har utvidet og styrket nettverksmodellen ved å ta utgangspunkt i nettverket selv. Hvor fokus til nå har vært på nettverksmodellen som overordnet styringsmodell, og nettverksanalyse og -presentasjon i et makroperspektiv, og hvor jeg også har sett på utviklingen i et mer historisk perspektiv, vil jeg nå foreta et lite fokusskift. Jeg vil i neste del av oppgaven se på hvordan noen praksiser for innholdsorganisering og -presentasjon internt på websteder har endret seg, og hvordan enkelte aktører mer enn noensinne har utvidet den sentralstyrte lesning med en lesningmodell lagt mer opp til en nettverkstankegang.
For å gjøre dette vil jeg ta for meg nok en suksesshistorie på web, nemlig Amazon. Amazon er interessant også fra et historisk perspektiv, da det var et av de første e-handelssteder man hadde på web, ble dømt til den sikre død, men overlevde og i dag kan melde om store overskudd. Jeg vil imidlertid velge en litt annen tilgang, og se på noen nye teknikker Amazon har tatt i bruk for å presentere innhold på sine sider – teknikker som først og fremst relaterer seg til hvordan de personaliserer webstedet til sine kunder og på den måten utvider den sentralstyrte modellen for innholdspresentasjon. I tillegg vil jeg komme inn på hvordan Amazon fungerer som et nettfellesskap, og hvordan de utnytter sine kunder og sitt kundenettverk til å skaffe mer data og mer trafikk til sine sider.
Dette var del 1 av oppgaven. Gå videre til del 2.
 Abonner på innlegg
Abonner på innlegg